|
I am an applied scientist at Amazon AGI. Before joining Amazon, I received my PhD degree from the Center for Research in Computer Vision (CRCV), University of Central Florida (UCF), under the supervision of Prof. Chen Chen. Before that, I received my bachelor's degree from University of Science and Technology of China (USTC). My current research mainly focuses on diffusion models and multimodal large language models. My work has been selected as CVPR'22 Best Paper Finalist, and ICCV'25 KnowledgeMR Workshop Best Benchmark Paper. Email / Google Scholar / Github / LinkedIn / |

|
|
|

|
Applied Scientist
Amazon AGI/AWS AI, Aug 2023 Building Amazon Nova foundation models. |

|
Applied Scientist Intern
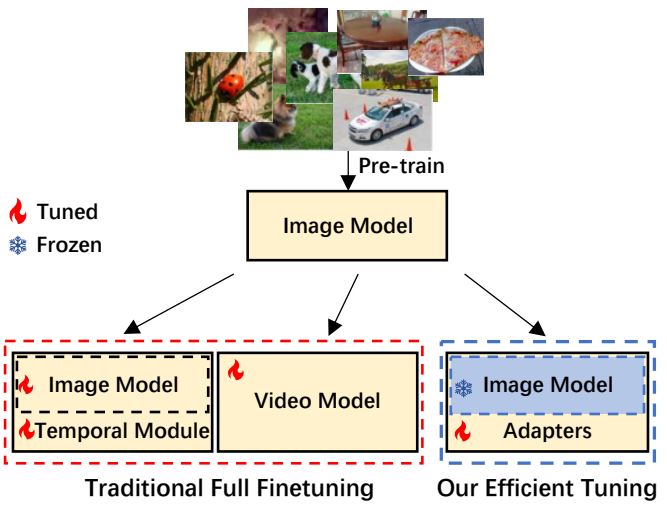
AWS AI Labs, Santa Clara, USA. Summer 2022 Host: Yi Zhu, Yusheng Xie, Aston Zhang, Mu Li Adapt image models for efficient video understanding. |

|
Research Intern
ByteDance Inc., Mountain View, USA. Summer 2021 Host: Linjie Yang, Xiaojie Jin Efficient neural architecture search. |
|
|
|
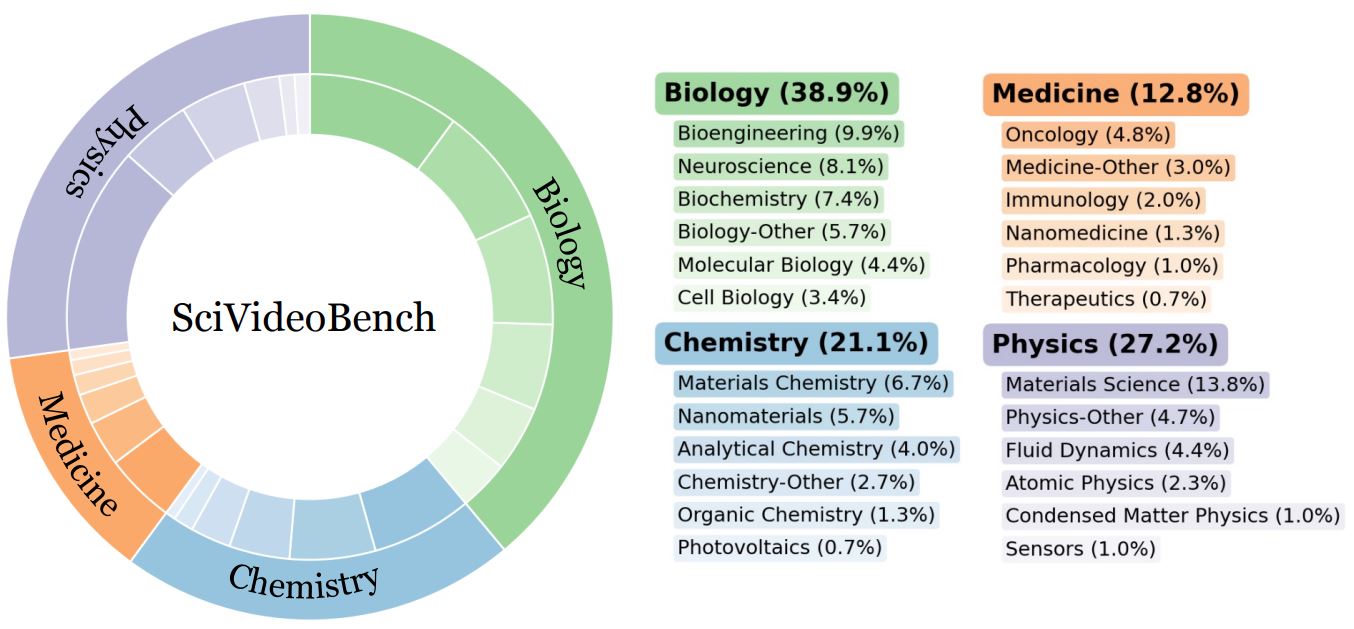
Andong Deng, Taojiannan Yang, Shoubin Yu, Lincoln Spencer, Mohit Bansal, Chen Chen, Serena Yeung-Levy, Xiaohan Wang Best Benchmark Paper Award at ICCV'25 KnowledgeMR workshop paper / code / leaderboard We introduce SciVideoBench, the first scientific video reasning benchmark. |
|
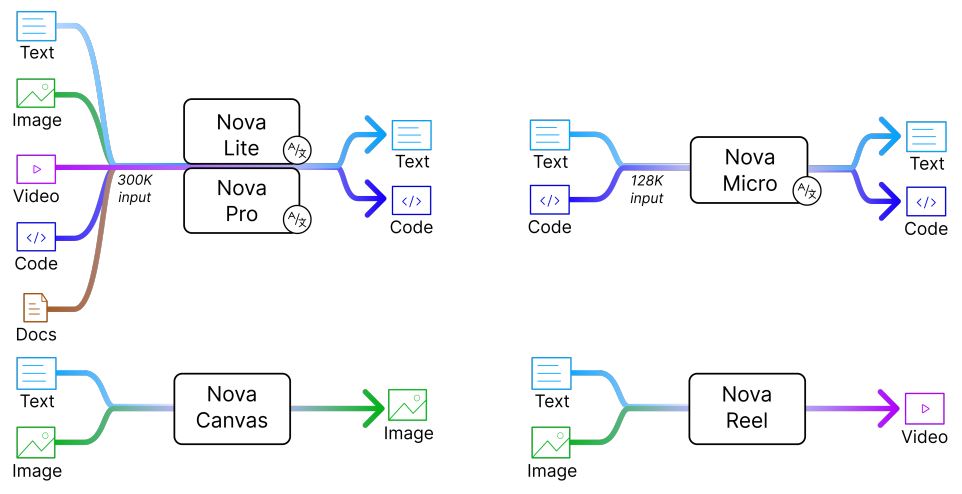
Core Contributor Amazon Science, 2024 paper We present Amazon Nova, a new generation of state-of-the-art foundation models that deliver frontier intelligence and industry-leading price performance. |
|
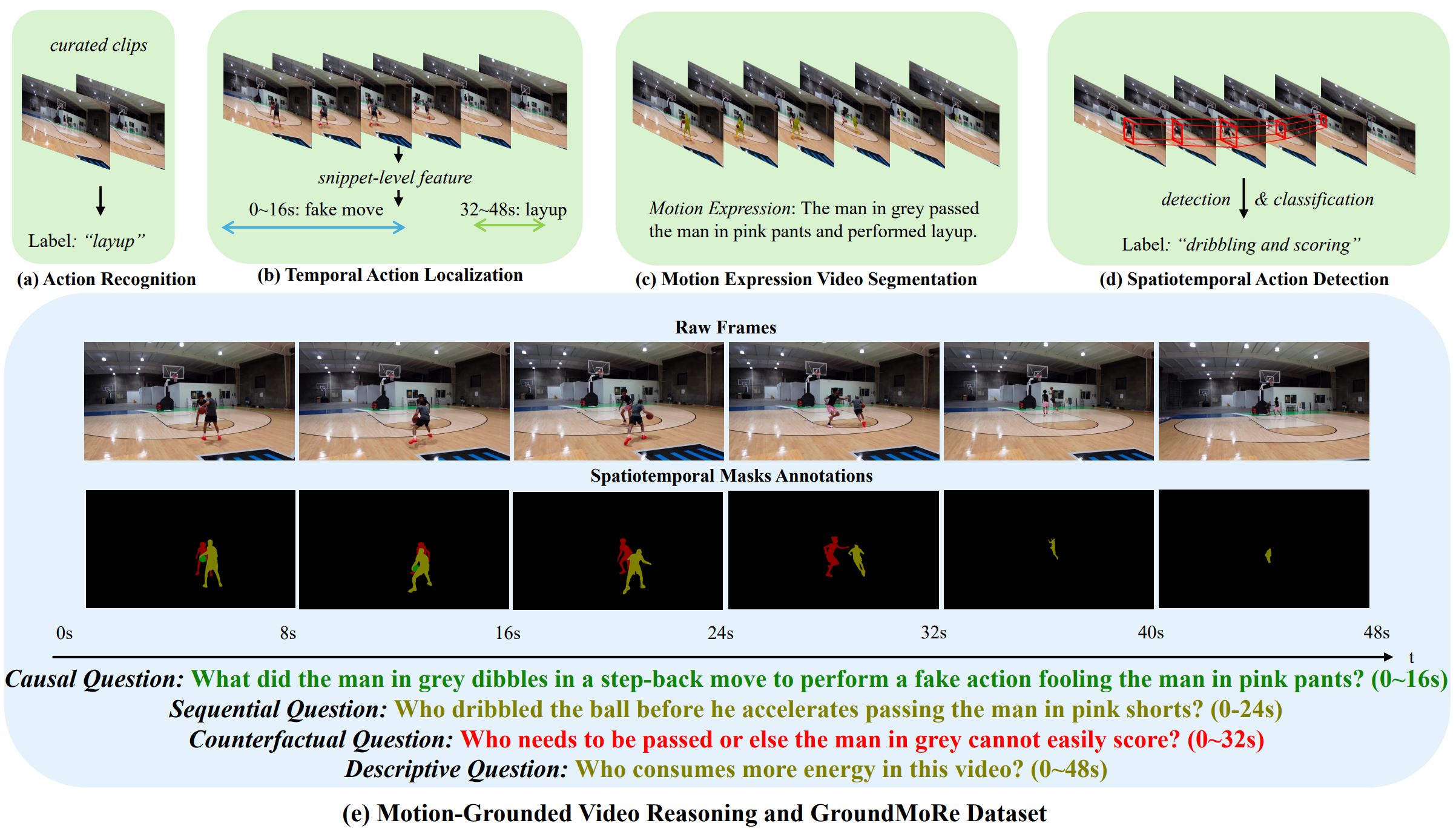
Andong Den, Tongjia Chen, Shoubin Yu, Taojiannan Yang, Lincoln Spencer, Yapeng Tian, Ajmal Saeed Mian, Mohit Bansal, Chen Chen IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 paper / code A new Motion-Grounded Video Reasoning benchmark, which evaluates multimodal models’ reasoning and perception capabilities for motion understanding. |
|
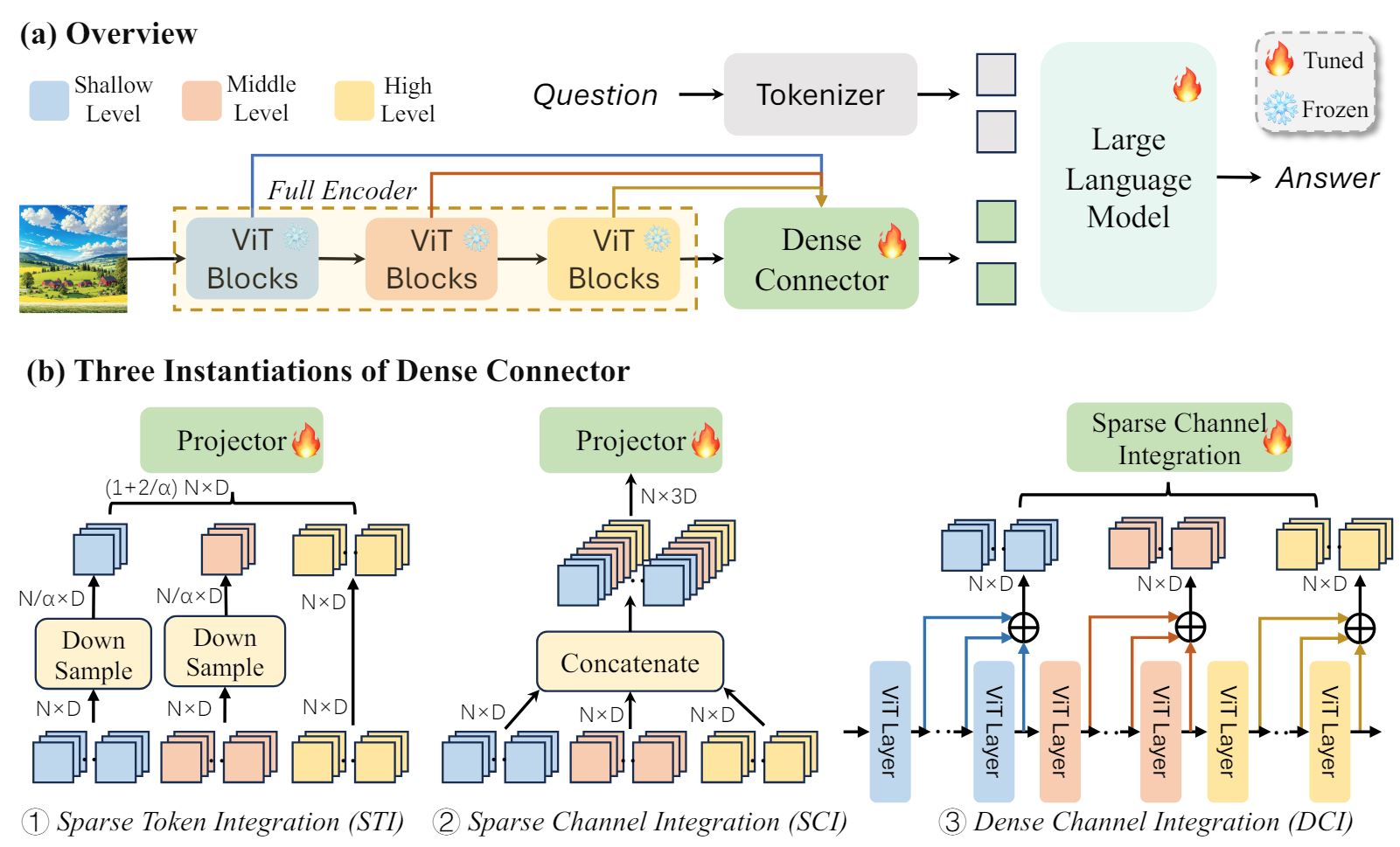
Huanjin Yao*, Wenhao Wu*, Taojiannan Yang, Yuxin Song, Mengxi Zhang, Haocheng Feng, Yifan Sun, Zhiheng Li, Wanli Ouyang, Jingdong Wang Neural Information Processing Systems (NeurIPS), 2024 paper / code A universal plug-and-play module to enhance Multimodal-LLM. |

|
Ming Li, Taojiannan Yang, Huafeng Kuang, Jie Wu, Zhaoning Wang, Xuefeng Xiao, Chen Chen. European Conference on Computer Vision (ECCV), 2024 paper / code / demo Improving the controllability of generative models through discriminative models. |

|
Andong Deng*, Taojiannan Yang*, Chen Chen. International Conference on Computer Vision (ICCV), 2023 paper / code and data A new comprehensive action recognition benchmark to evaluate spatiotemporal representation learning from various perspectives. |
|
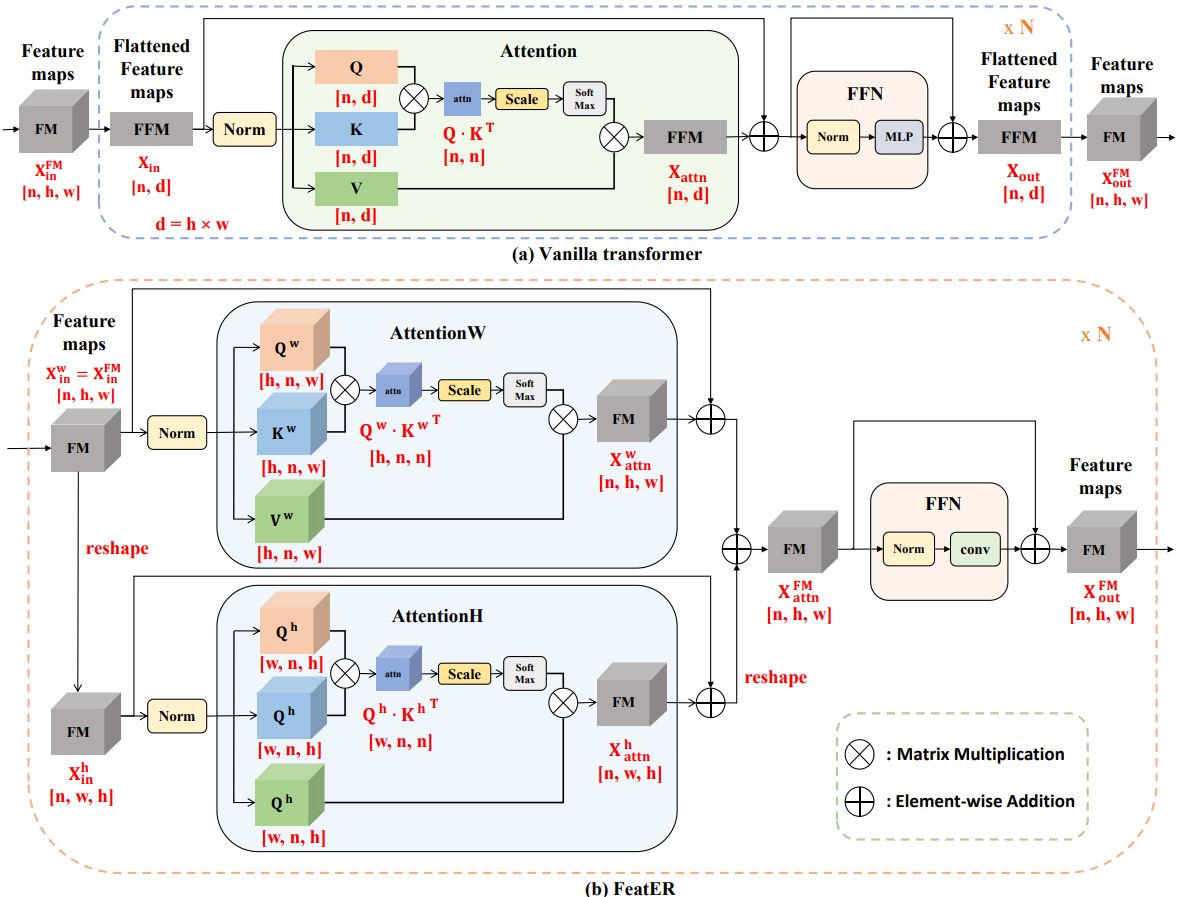
Taojiannan Yang, Yi Zhu, Yusheng Xie, Aston Zhang, Chen Chen, Mu Li. International Conference on Learning Representations (ICLR), 2023 paper / project / code How to efficiently and effectively adapt image models for video understanding. |

|
Taojiannan Yang, Linjie Yang, Xiaojie Jin, Chen Chen. Winter Conference on Applications of Computer Vision (WACV), 2023 paper / code Training-free metrics are highly correlated with #params and we propose a new efficient training-based method to address the problem. |
|
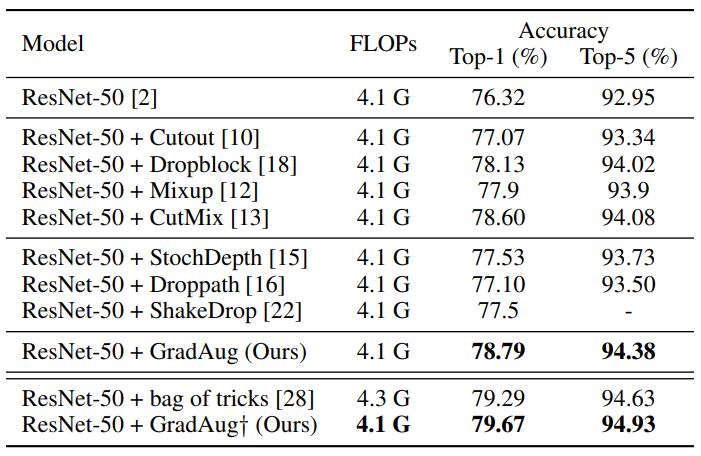
Matias Mendieta, Taojiannan Yang, Pu Wang, Minwoo Lee, Zhengming Ding, Chen Chen. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 (Best Paper Finalist, 33 out of 8161) paper / code GradAug alleviates data heterogeneity in federated learning by smoothing loss landscape. We further improve its efficiency by proposing a new method FedAlign. |

|
Taojiannan Yang, Sijie Zhu, Matias Mendieta, Pu Wang, Ravikumar Balakrishnan, Minwoo Lee, Tao Han, Mubarak Shah, Chen Chen. IEEE Transaction on Pattern Analysis and Machine Intelligence (TPAMI), 2021 paper / code We extend MutualNet to learn adaptive video models and conduct more analyses. |
|
Taojiannan Yang, Sijie Zhu, Chen Chen. Neural Information Processing Systems (NeurIPS), 2020 paper / code A well-generalized network should make predictions consistent with its subnetworks given differently augmented samples. |

|
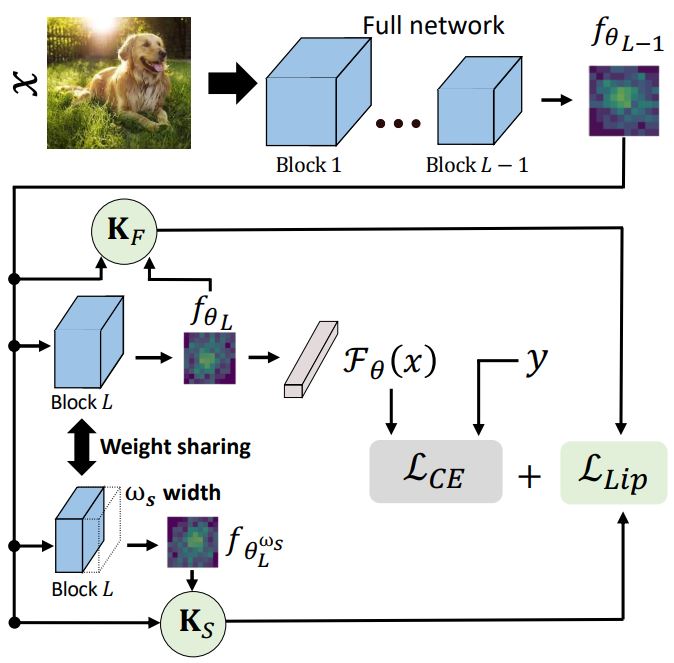
Taojiannan Yang, Sijie Zhu, Chen Chen, Shen Yan, Mi Zhang, Andrew Willis. European Conference on Computer Vision (ECCV), 2020 (Oral Presentation, 104 out of 5205) paper / code We learn networks that can run at different widths and resolutions to meet different resource budegets during runtime. |
|
Ce Zheng, Matias, Mendieta, Taojiannan Yang, Guojun Qi, Chen Chen. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023 paper / code An efficent method for human pose estimation and mesh reconstruction. |
|
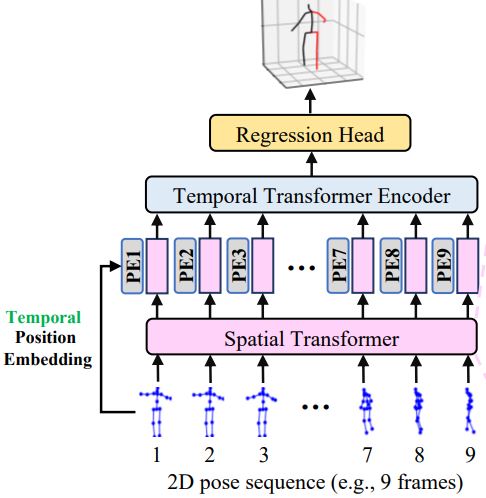
Ce Zheng, Sijie Zhu, Matias Mendieta, Taojiannan Yang, Chen Chen, Zhengming Ding. International Conference on Computer Vision (ICCV), 2021 paper / code A spatial-temporal transformer structure for 3D human pose estimation. |
|
|
Sijie Zhu, Taojiannan Yang, Chen Chen. IEEE Transactions on Image Processing (TIP), 2021 paper / code We visualize point-to-point activation intensity between two images. |
|
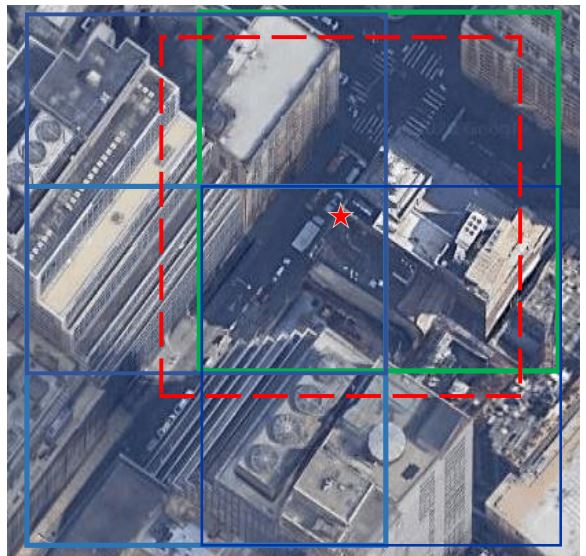
Sijie Zhu, Taojiannan Yang, Chen Chen. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021 paper / code A new benchmark for more realistic cross-view image geo-localization. |
|
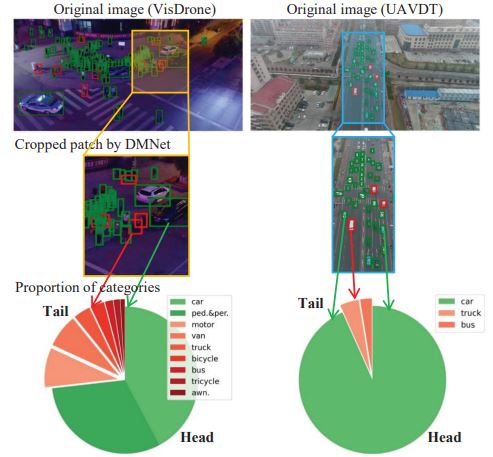
Weiping Yu*, Taojiannan Yang*, Chen Chen. Winter Conference on Applications of Computer Vision (WACV), 2021 paper / code We point out the long-tail distribution problem in UAV images and propose a new method to address it. |
|
|

|
Feel free to steal this website's source code. Do not scrape the HTML from this page itself, as it includes analytics tags that you do not want on your own website — use the github code instead. Also, consider using Leonid Keselman's Jekyll fork of this page. |